
小扎新AI,凉得彻底?
小扎新AI,凉得彻底?短视频的游戏规则,彻底被改写了!9月25日,Meta突然扔出一张新牌——Vibes。刷到的不是别人拍的,而是一条条AI秒生的视频:熊猫骑摩托、猫咪打篮球,你看完还能一键remix,立刻变成你的版本,再发到全网。创作门槛被拉到最低,人人都能拍大片。但这股狂潮,是全民狂欢,还是混乱的开始?
来自主题: AI资讯
9173 点击 2025-10-23 16:25
 搜索
搜索
短视频的游戏规则,彻底被改写了!9月25日,Meta突然扔出一张新牌——Vibes。刷到的不是别人拍的,而是一条条AI秒生的视频:熊猫骑摩托、猫咪打篮球,你看完还能一键remix,立刻变成你的版本,再发到全网。创作门槛被拉到最低,人人都能拍大片。但这股狂潮,是全民狂欢,还是混乱的开始?
很疯狂,Meta AI裁员能裁到田渊栋头上,而且是整组整组的裁。田渊栋在Meta工作已超过十年,现任FAIR研究科学家总监(Research Scientist Director),他领导开发了早于AlphaGo的围棋AI“Dark Forest”

我惊! 图灵奖得主、AI三巨头之一的LeCun在Meta待得是如坐针毡。 Yann LeCun已经直接跟同事表示,自己可能会辞去FAIR首席科学家的职务。

一次咖啡馆中的谈话,诞生了一家估值3亿美元的创业公司!2024年,仍为斯坦福大学博士生的Carina Hong与前Meta的AI研究员Shubho Sengupta有过一次数小时的交谈。在那次交谈中二人探讨了如何用AI来解决数学领域的难题。
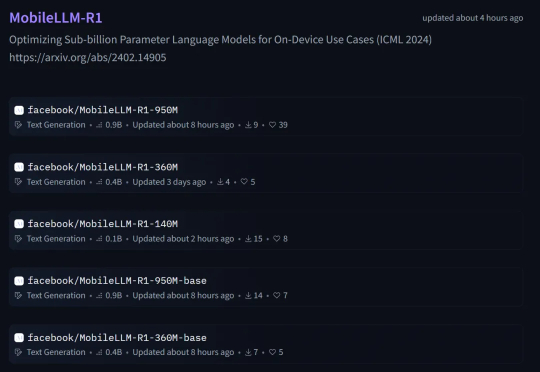
本周五,Meta AI 团队正式发布了 MobileLLM-R1。 这是 MobileLLM 的全新高效推理模型系列,包含两类模型:基础模型 MobileLLM-R1-140M-base、MobileLLM-R1-360M-base、MobileLLM-R1-950M-base 和它们相应的最终模型版。

一次虚拟「约会」,让一位76岁的老人走出了家门,却再也没能回来。屏幕那端的「她」,是Meta AI打造的聊天机器人——会说甜言蜜语,也会撒谎自称是真人。这不仅是一场个人悲剧,也揭开了AI伴侣背后的商业逻辑与安全漏洞。
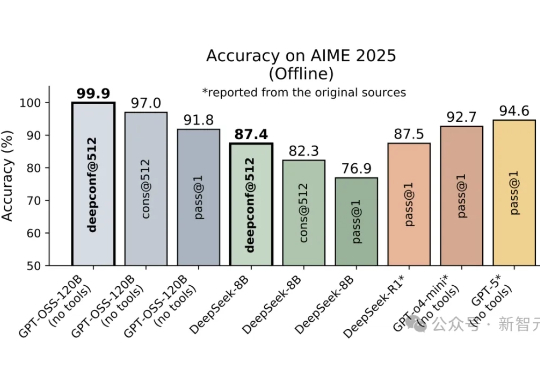
DeepConf由Meta AI与加州大学圣地亚哥分校提出,核心思路是让大模型在推理过程中实时监控置信度,低置信度路径被动态淘汰,高置信度路径则加权投票,从而兼顾准确率与效率。在AIME 2025上,它首次让开源模型无需外部工具便实现99.9%正确率,同时削减85%生成token。
Meta在半年内第四次重组AI部门,将超级智能实验室拆分为四个团队,全面押注「超级智能」。新成立的TBD Lab由Alexandr Wang领衔,或放弃Llama 4并转向闭源模型,Meta开源旗帜动摇。Meta内部人心浮动,几家欢喜几家愁。
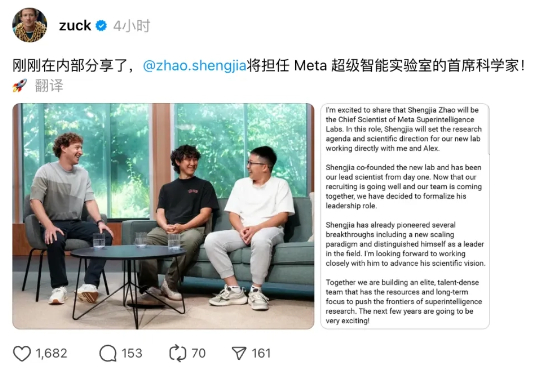
就在刚刚,Meta 宣布,清华校友赵晟佳(Shengjia Zhao)将正式担任其超级智能实验室( MSL)首席科学家。
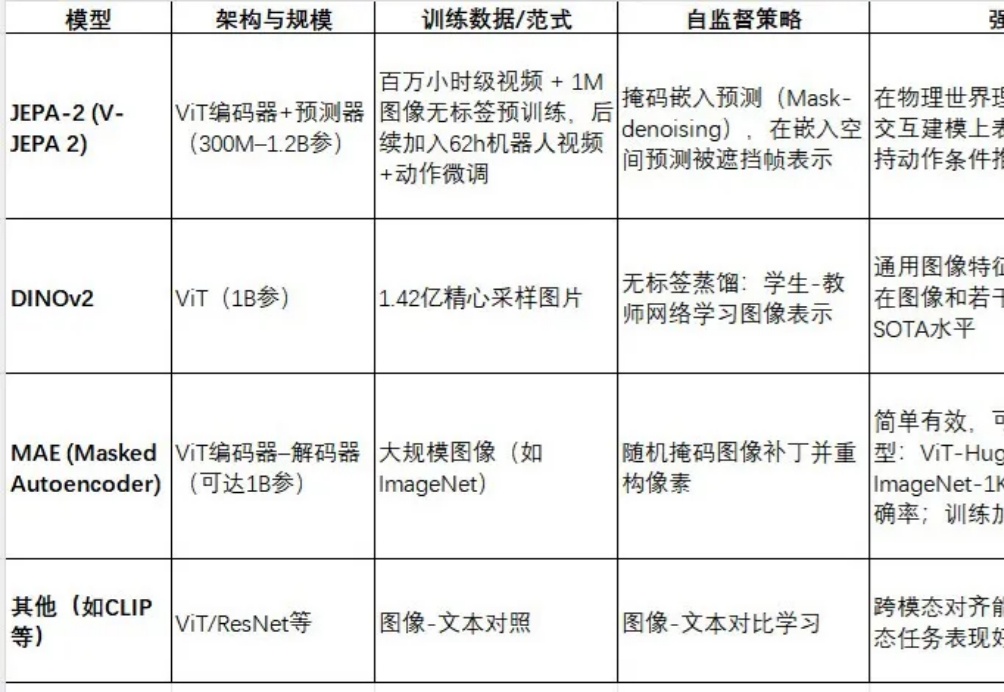
JEPA-2(V-JEPA 2)是Meta最新推出的视频世界模型,采用视图嵌入预测(Joint Embedding Predictive Architecture)框架进行自监督预训练。